Glossier YouTube Data Mining and Analysis
Glossier is not a mainstream brand, but has a cult-like following -- so, why has this brand become so successful?
Many of the products are formed by the company mining social media comments for the most commonly requested product and polling their followers.
80% of millennials say they trust a stranger’s recommendation as much as a loved one’s. Glossier has taken this and created marketing campaigns that feature everyday women using Glossier products created to seem genuine and organic.
To remain relevant, brands have to provide consistent and high quality content on all digital platforms, and Glossier’s social media content strategy positions the brand as authentic and down-to-earth, without using salesy language, as if their brand is just another friend’s Instagram page. They try to appear consciously authentic and as if not overly calculated.
Since many of the products are formed by the company mining social media comments for the most commonly requested product, this approach can also be applied to provide the type of marketing that their following wants to see the most.
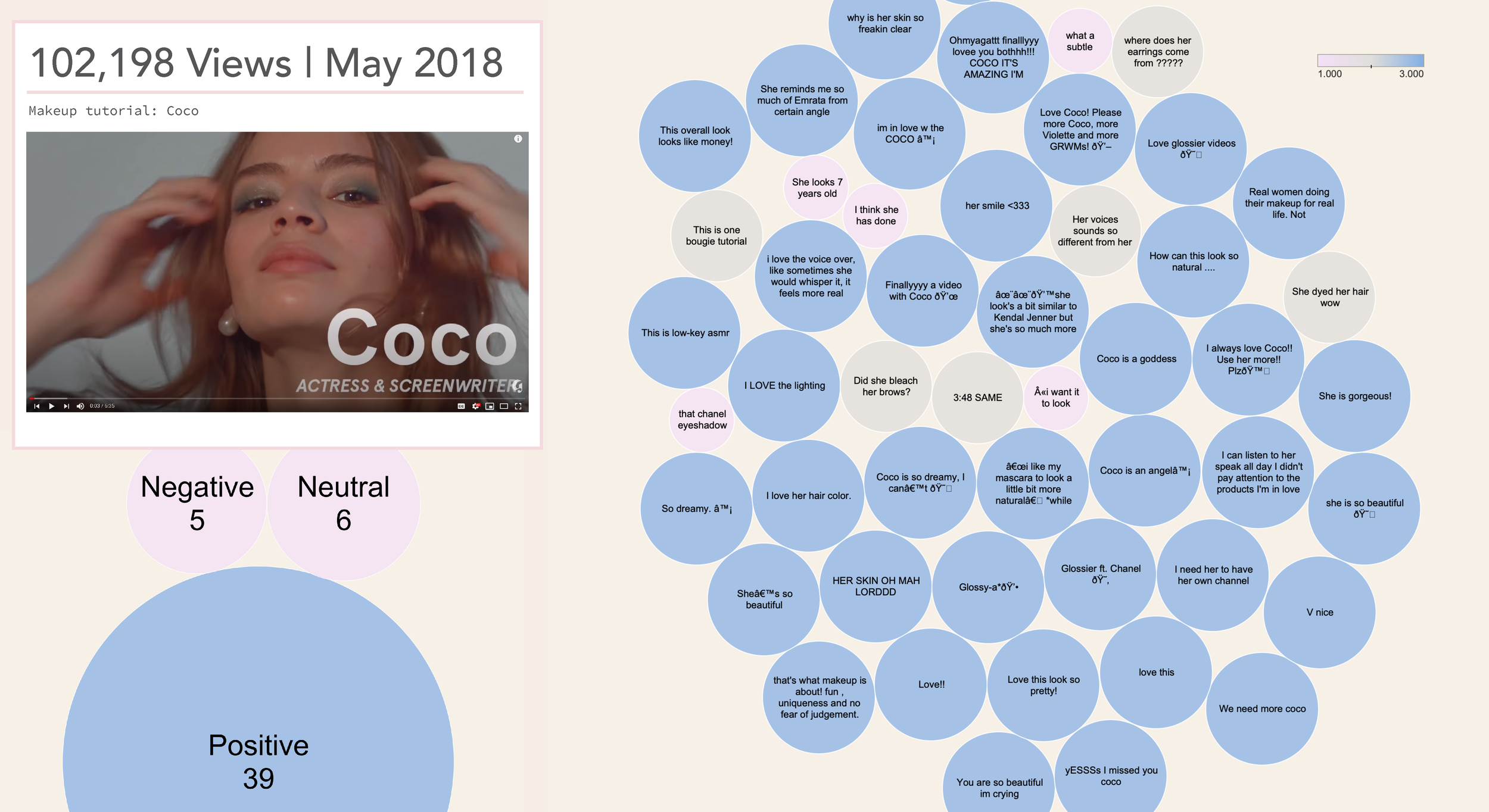
This case study aimed to do just that by scraping the YouTube comments from Glossier’s video advertising campaigns which feature everyday people and semi-celebrities getting ready for the day using Glossier products. Along with micro-influencer and user-generated centric social media marketing, these videos are heavily used as sponsored ads as their target audience spends time on YouTube.
Of Glossier’s YouTube presence, fourteen marketing campaign videos were scraped with a Python code for 50 comments each, totaling 700 comments. The comments were analyzed on a sentiment scale of one to three, one being “negative” sentiment, two being “neutral” sentiment, and three being “positive” sentiment. The comments were also read through for the frequency of themes for positive or negative sentiments to come up with recommendations.
Scrape comments from each YouTube video with Python
First, the comments were run through another Python script to randomize the convenient sample so that there were 50 random comments for each of the fourteen videos to analyze.
import lxml
import requests
import time
import sys
#import progressbar as PB
YOUTUBE_IN_LINK = 'https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&maxResults=100&order=relevance&pageToken={pageToken}&videoId={videoId}&key={key}'
YOUTUBE_LINK = 'https://www.googleapis.com/youtube/v3/commentThreads?part=snippet&maxResults=100&order=relevance&videoId={videoId}&key={key}'
key = 'AIzaSyBTKgPj7yZXod-hnc939rDlsDqXfIgQccE' #Step 1: Copy and paste your youtube API here
def commentExtract(videoId):
print ("Comments downloading")
page_info = requests.get(YOUTUBE_LINK.format(videoId = videoId, key = key))
while page_info.status_code != 200:
if page_info.status_code != 429:
print ("Comments disabled")
sys.exit()
time.sleep(20)
page_info = requests.get(YOUTUBE_LINK.format(videoId = videoId, key = key))
page_info = page_info.json()
comments = []
for i in range(len(page_info['items'])):
comments.append(page_info['items'][i]['snippet']['topLevelComment']['snippet']['textOriginal'])
numberofpages=0
while numberofpages<14 and 'nextPageToken' in page_info:
numberofpages=numberofpages+1
temp = page_info
page_info = requests.get(YOUTUBE_IN_LINK.format(videoId = videoId, key = key, pageToken = page_info['nextPageToken']))
while page_info.status_code != 200:
time.sleep(10)
page_info = requests.get(YOUTUBE_IN_LINK.format(videoId = videoId, key = key, pageToken = temp['nextPageToken']))
page_info = page_info.json()
for i in range(len(page_info['items'])):
comments.append(page_info['items'][i]['snippet']['topLevelComment']['snippet']['textOriginal'])
return comments
comments=commentExtract("Nqx4cnBmTks") #Step 2: Copy and paste the video key here. Video key is after the "=" sign.
comments
Convert the data to a Pandas dataframe and export it to .CSV files
Once the data is exported to .CSV files, it was manually analyzed for positive, negative, or neutral sentiment as machine learning isn’t advanced enough yet to do this.
import pandas as pd
df = pd.DataFrame(comments)
df.to_csv('glossier_get_ready_with_me_delilah.csv') #Step 3: You could change the file name here.
df = df.sample (50) #Step 4: You could change your random sample size here.
display (df)
df.to_csv('glossier_get_ready_with_me_delilah.csv') #Step 5: Your random sample will be saved as an Excel file.